My understanding of object detection is to accurately find the location of the object in a given picture and mark the category of the object. The problem to be solved by object detection is where the object is and what is the problem of the whole process. However, this problem is not so easy to solve. The size of the object can vary widely, the angle of the object is placed, the posture is uncertain, and it can appear anywhere in the picture, not to mention the object can also be of multiple categories.
The evolution of object detection technology: RCNN->SppNET->Fast-RCNN->Faster-RCNN
Speaking of the task of image recognition, there is an image task: it is necessary to identify the object in the picture, but also to use a box to frame its position.
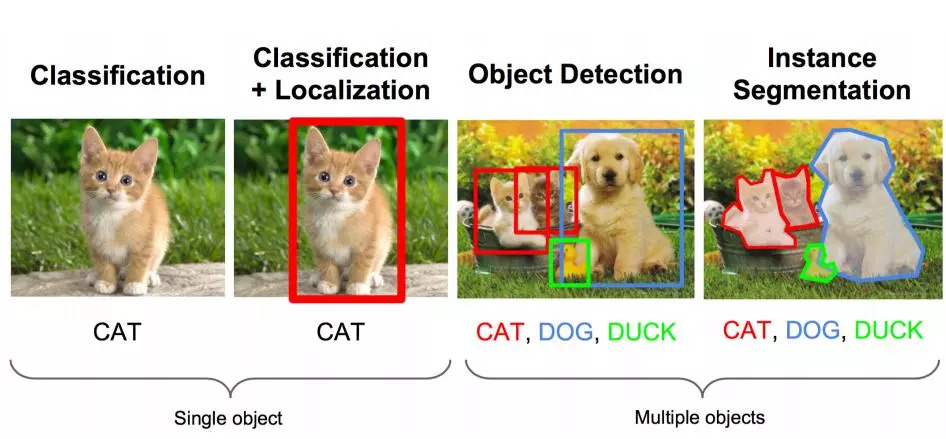
The above task in professional terms is: image recognition + positioning image recognition (classification): input: image output: object category evaluation method: accuracy

Localization: Input: Picture Output: The position of the box in the picture (x, y, w, h) Evaluation method: Detection evaluation function intersection-over-union (IOU)

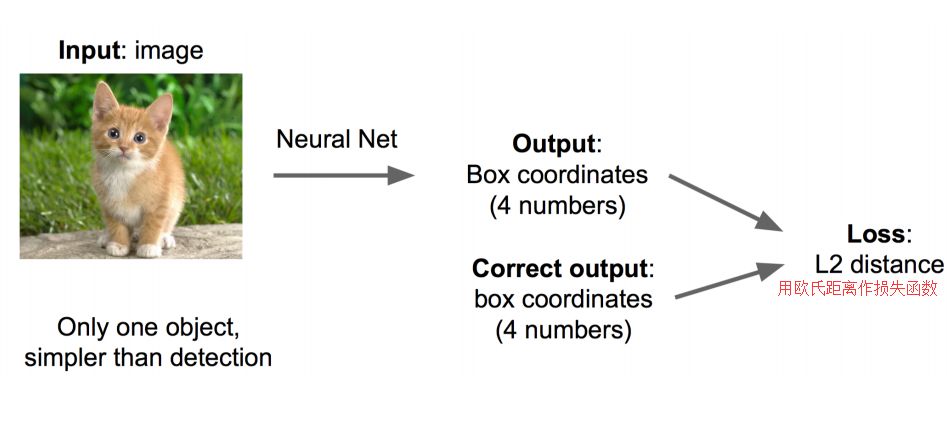
The convolutional neural network CNN has already helped us complete the task of image recognition (determining whether it is a cat or a dog). We only need to add some additional functions to complete the positioning task.
What are the solutions to the positioning problem? Idea 1: Regarding a regression problem as a regression problem, we need to predict the values ​​of the four parameters (x, y, w, h) to get the position of the box.
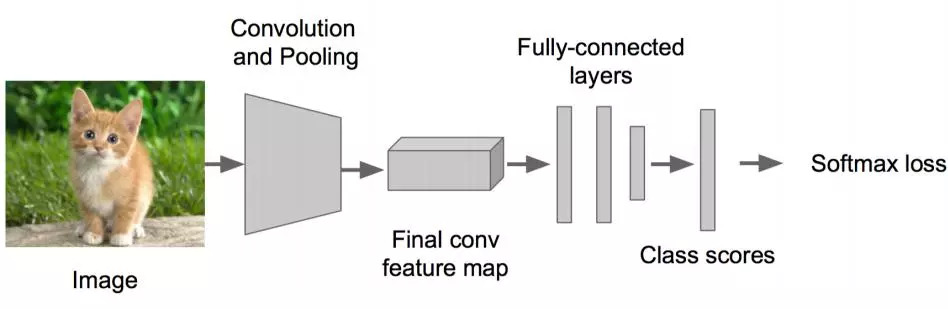
Step 1: • Solve simple problems first, build a neural network that recognizes images • Fine-tuning on AlexNet VGG GoogleLenet
Step 2: • Expand at the tail of the above neural network (that is, the front of CNN remains unchanged, we make an improvement at the end of CNN: add two heads: "classification head" and "regression head") • become classification + regression mode
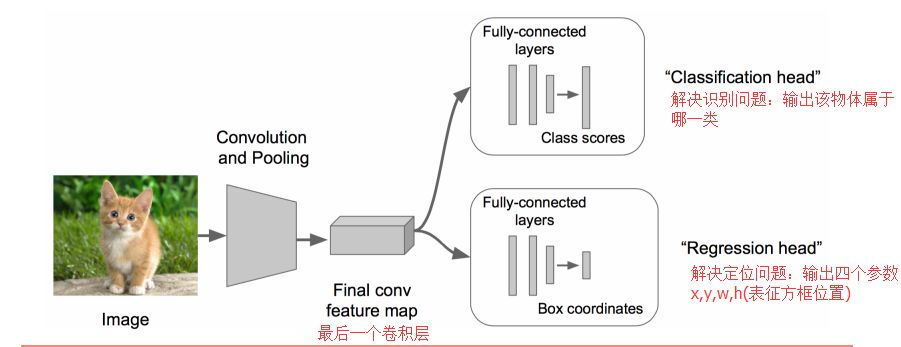
Step 3: • Use Euclidean distance loss for the part of Regression • Use SGD to train
Step 4: • Put the two heads together in the prediction stage • Complete different functions
Here you need to perform fine-tuning twice. The first time you do it on ALexNet, the second time you change the head to regression head, the previous time is unchanged, and one fine-tuning is done.
Where is the Regression part added?
There are two processing methods: • added after the last convolutional layer (such as VGG) • added after the last fully connected layer (such as R-CNN)
Regression is too difficult to do, and we should find ways to convert it into a classification problem. The training parameters of regression take much longer to converge, so the above network uses a classification network to calculate the connection weights of the common parts of the network.
Idea 2: Take the image window • Or the classification + regression idea just now • Let's take different sizes of "boxes" • Let the boxes appear in different positions, and get the judgment score of this box • The box with the highest score
Black box in the upper left corner: score 0.5

Black box in the upper right corner: score 0.75

The black box in the lower left corner: score 0.6

The black box in the lower right corner: score 0.8

According to the score, we chose the black box in the lower right corner as the prediction of the target position. Note: Sometimes the two boxes with the highest scores are also selected, and then the intersection of the two boxes is taken as the final position prediction.
Doubt: How big should the frame be? Take different boxes and swipe from the upper left corner to the lower right corner in turn. Very rude.
Summarize the idea: For a picture, use boxes of various sizes (traversing the entire picture) to intercept the picture, input it to CNN, and then CNN will output the score of this box (classification) and the corresponding x, y of this box picture ,h,w (regression).
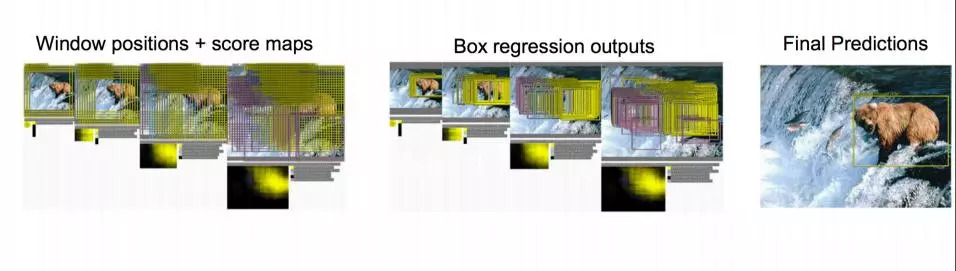
This method is too time-consuming, make an optimization. It turns out that the network is like this:
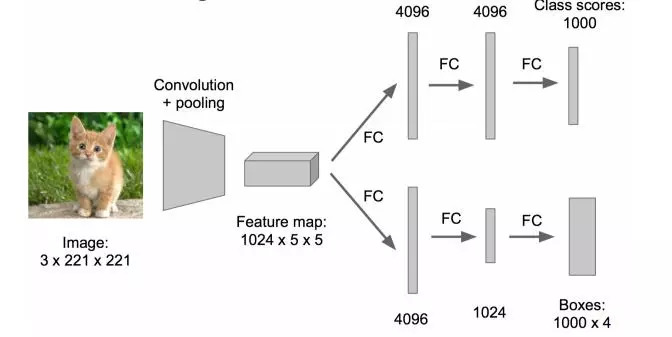
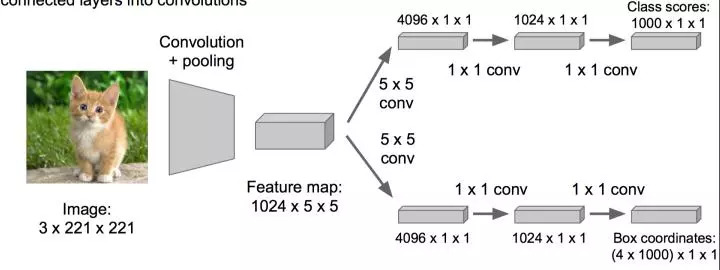
Optimized like this: change the fully connected layer to a convolutional layer, which can speed up.
Object Detection (Object Detection) What to do when there are many objects in the image? The difficulty suddenly increased.
Then the task becomes: multi-object recognition + locating multiple objects. What about this task as a classification problem?

What's wrong with seeing it as a classification problem? • You need to find a lot of locations and give a lot of frames of different sizes. You also need to classify the images in the frames. Of course, if your GPU is very powerful, well, go ahead and do it...
Regarding classification, is there any way to optimize it? I don't want to try so many boxes and so many positions! Someone thinks of a good method: find out the boxes that may contain objects (that is, candidate boxes, for example, select 1000 candidate boxes). These boxes can overlap each other and contain each other, so that we can avoid all the boxes that are enumerated by violence Up.

The big cows have invented many methods of selecting candidate boxes, such as EdgeBoxes and Selective Search. The following is a performance comparison of various methods of selecting candidate frames.
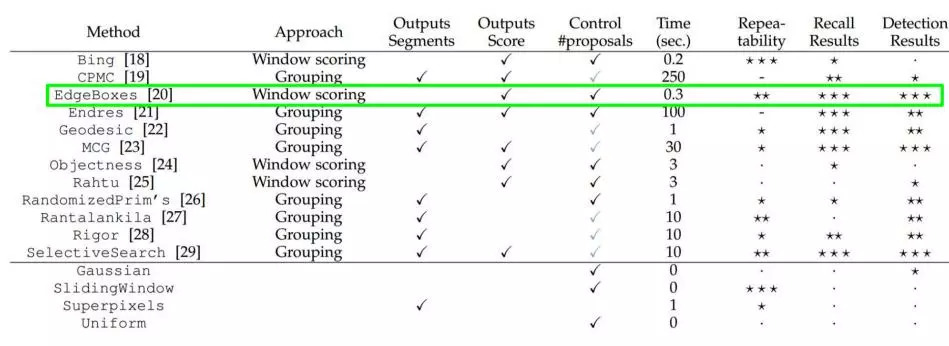
There is a big doubt. How does the "selective search" algorithm used to extract candidate boxes select these candidate boxes? You have to take a good look at its papers, so I won’t introduce them here.
R-CNN turned out
Based on the above ideas, RCNN appeared.
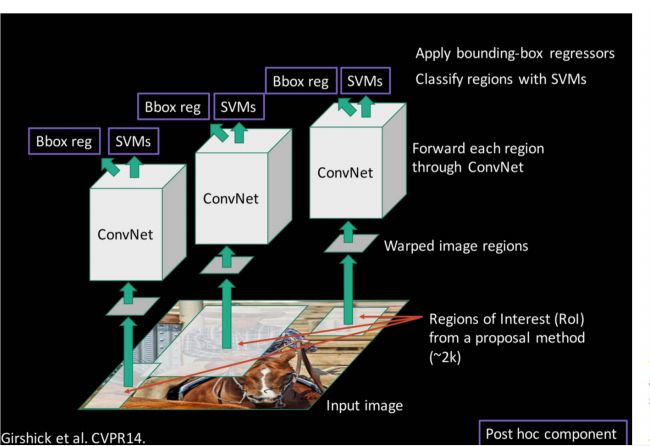
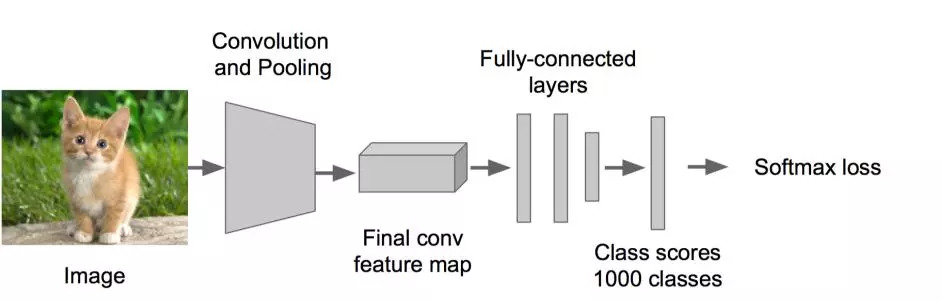
Step 1: Train (or download) a classification model (such as AlexNet)
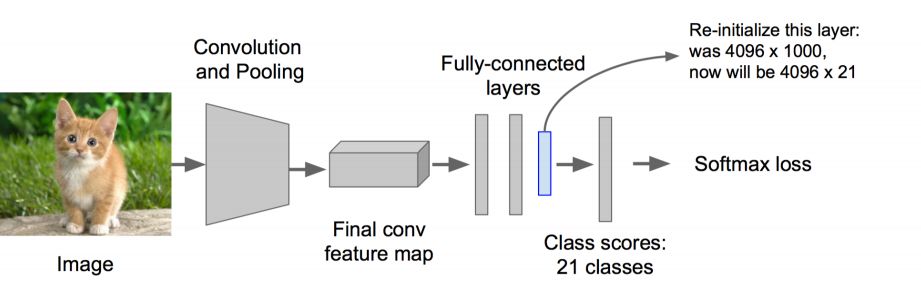
Step 2: Perform fine-tuning on the model• Change the number of classifications from 1000 to 20• Remove the last fully connected layer
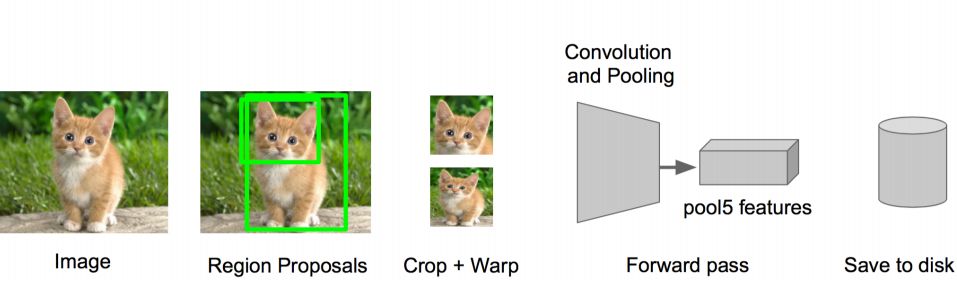
Step 3: Feature extraction • Extract all candidate frames of the image (selective search) • For each region: modify the size of the region to fit the input of CNN, do a forward calculation, and take the output of the fifth pooling layer (that is, right The features extracted from the candidate frame) are saved to the hard disk
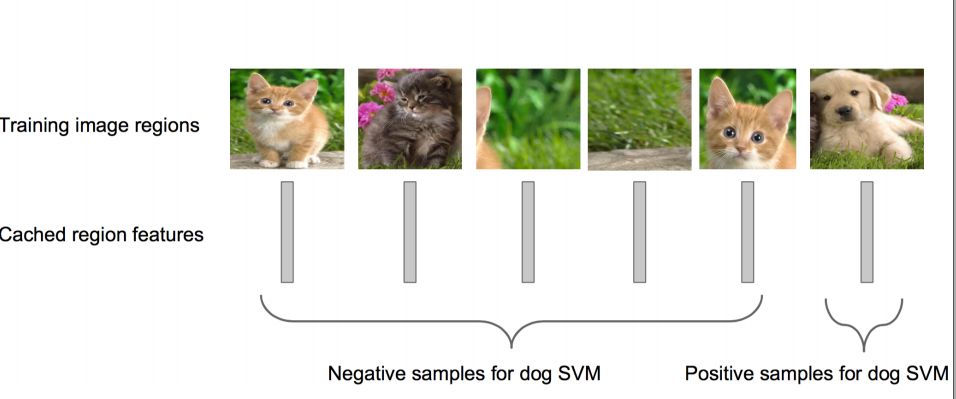
Step 4: Train an SVM classifier (two classifications) to determine the category of the object in the candidate box. Each category corresponds to an SVM. To determine whether it belongs to this category, it is positive. On the contrary, nagative. For example, as shown in the figure below, it is the SVM for dog classification.
Step 5: Use the regression to fine-tune the position of the candidate frame: For each class, train a linear regression model to determine whether the frame is perfect.

In the evolution of RCNN, the idea of ​​SPP Net has contributed a lot to it. Here is a brief introduction to SPP Net.
SPP NetSPP: Spatial Pyramid Pooling (spatial pyramid pooling) It has two characteristics:
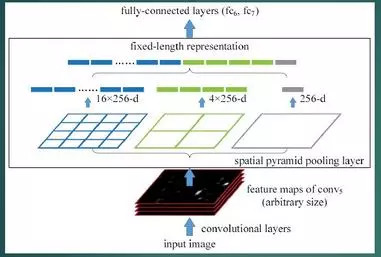
1. Combine the spatial pyramid method to achieve the scale input of CNNs. Generally, CNN is followed by a fully connected layer or a classifier. They all need a fixed input size, so they have to crop or warp the input data. These preprocessing will cause data loss or geometric distortion. The first contribution of SPP Net is to add the pyramid idea to CNN to realize the multi-scale input of data.
As shown in the figure below, an SPP layer is added between the convolutional layer and the fully connected layer. At this time, the input of the network can be of any scale. Each pooling filter in the SPP layer will be resized according to the input, and the output scale of the SPP is always fixed.
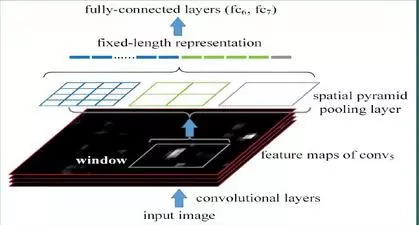
2. Only extract convolutional features once for the original image
In R-CNN, each candidate frame is first resized to a uniform size, and then used as the input of CNN separately, which is very inefficient. So SPP Net is optimized based on this shortcoming: only convolve the original image once to get the feature map of the entire image, and then find the mapping patch on the zaifeature map of each candidate frame, and use this patch as the convolution of each candidate frame. The features are input to the SPP layer and subsequent layers. It saves a lot of calculation time and is about a hundred times faster than R-CNN.
Fast R-CNNSPP Net is really a good method. The advanced version of R-CNN, Fast R-CNN, adopts the SPP Net method on the basis of RCNN, and improves RCNN to further improve its performance.
What are the differences between R-CNN and Fast RCNN? Let me talk about the shortcomings of RCNN first: even if preprocessing steps such as selective search are used to extract potential bounding boxes as input, RCNN will still have serious speed bottlenecks. The reason is obvious, that is, when the computer performs feature extraction on all regions. Repeated calculations, Fast-RCNN was born to solve this problem.
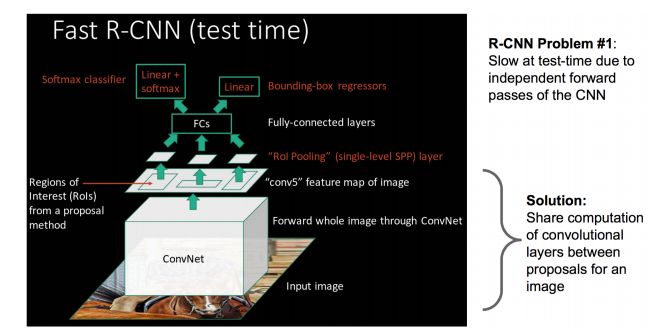
Daniel proposed a network layer that can be regarded as a single-layer sppnet, called ROI Pooling. This network layer can map inputs of different sizes to a fixed-scale feature vector, and we know that conv, pooling, relu and other operations are not available. A fixed size input is required. Therefore, after performing these operations on the original image, although the size of the input image is different, the resulting feature map size is also different. It cannot be directly connected to a fully connected layer for classification, but this magical ROI Pooling can be added. Layer, extract a fixed-dimensional feature representation for each region, and then perform type recognition through normal softmax. In addition, the previous RCNN processing flow was to first mention the proposal, then CNN to extract the features, then use the SVM classifier, and finally do bbox regression, and in Fast-RCNN, the author cleverly put bbox regression into the neural network, and The region classification and merge become a multi-task model. Actual experiments have also proved that these two tasks can share convolution features and promote each other. A very important contribution of Fast-RCNN is that it has successfully let people see the hope of real-time detection in the Region Proposal+CNN framework. The original multi-class detection can really improve the processing speed while ensuring the accuracy, which is also for the later Faster- RCNN laid the groundwork.
Draw a key point: R-CNN has some considerable shortcomings (all these shortcomings are corrected, it becomes Fast R-CNN). Big disadvantage: Since each candidate frame has to go through CNN alone, it takes a lot of time. Solution: Shared convolutional layer, now not every candidate box enters the CNN as input, but a complete picture, and then the characteristics of each candidate box are obtained in the fifth convolutional layer
The original method: many candidate boxes (such as two thousand) --> CNN --> get the characteristics of each candidate box --> classification + regression. The current method: a complete picture --> CNN --> get every Features of Zhang Candidate Box-->Classification + Regression
Therefore, it is easy to see that the reason for the speedup of Fast RCNN relative to RCNN is: but unlike RCNN, each candidate area is characterized by the deep network, but the entire image is extracted once, and the candidate frame is mapped to conv5, while SPP It only needs to calculate the features once, and the rest only needs to be operated on the conv5 layer.
The performance improvement is also quite obvious:
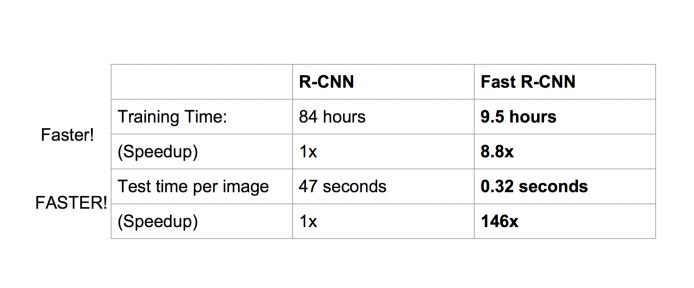
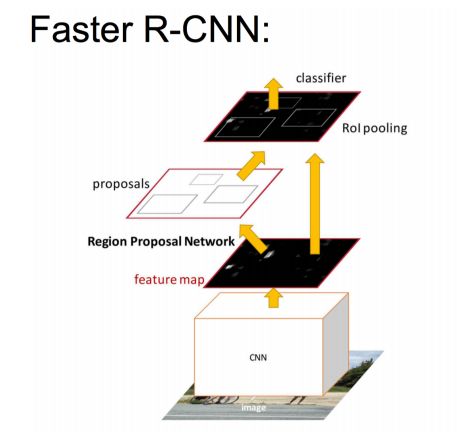
The problem with Faster R-CNN Fast R-CNN: There is a bottleneck: selective search to find all the candidate boxes, this is also very time-consuming. Can we find a more efficient method to find these candidate boxes? Solution: Add a neural network that extracts edges, that is to say, the job of finding candidate frames is also handed over to the neural network. The neural network that does such a task is called the Region Proposal Network (RPN).
Specific methods: • Put the RPN behind the last convolutional layer • RPN directly train to get the candidate area
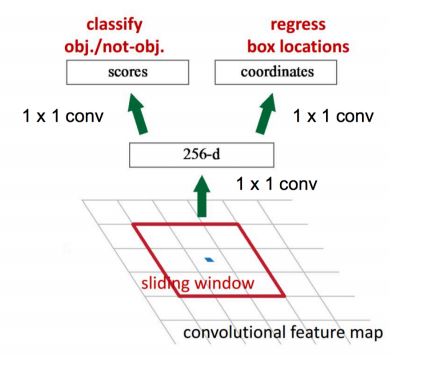
Introduction to RPN: • Sliding the window on the feature map • Building a neural network for object classification + box position regression • The position of the sliding window provides the general position information of the object • The box regression provides a more accurate position of the box
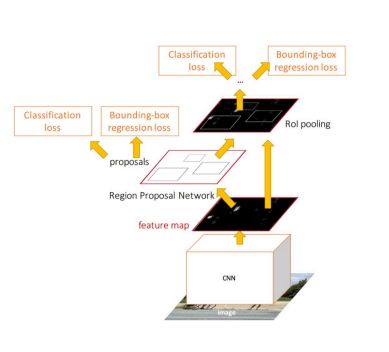
One kind of network, four loss functions;• RPN calssification(anchor good.bad)• RPN regression(anchor->propoasal)• Fast R-CNN classification(over classes)• Fast R-CNN regression(proposal ->box)
Speed ​​comparison
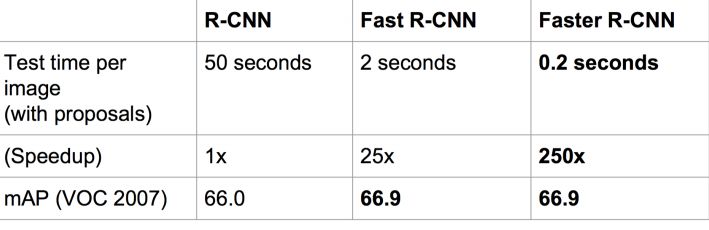
The main contribution of Faster R-CNN is to design a network RPN for extracting candidate regions, instead of time-consuming selective search, which greatly improves the detection speed.
Finally, summarize the steps of the major algorithms: RCNN 1. Determine about 1000-2000 candidate boxes in the image (using selective search) 2. Zoom to the same size of the image block in each candidate box, and input it into the CNN for feature extraction 3. For the features extracted from the candidate box, use the classifier to determine whether they belong to a specific class. 4. For the candidate box belonging to a certain feature, use a regression to further adjust its position
Fast RCNN1. Determine about 1000-2000 candidate boxes in the image (using selective search) 2. Input the entire image into CNN to get the feature map 3. Find the mapping patch of each candidate box on the feature map, and apply this patch As the convolution feature of each candidate box, input to the SPP layer and the subsequent layers 4. For the features extracted from the candidate box, use the classifier to determine whether it belongs to a specific class. 5. For the candidate box belonging to a certain feature, use regression Further adjust its position
Faster RCNN1. Input the entire picture into CNN to get the feature map2. Input the convolutional features into RPN to get the feature information of the candidate box 3. Use the classifier to determine whether the features extracted from the candidate box belong to a specific class 4. For the candidate frame belonging to a certain feature, use the regression to further adjust its position
In general, from R-CNN, SPP-NET, Fast R-CNN, Faster R-CNN along the way, the process of target detection based on deep learning has become more and more streamlined, with higher precision and higher speed. Come sooner. It can be said that the R-CNN series target detection method based on the region proposal is the most important branch in the current target detection technology field.
Cummins 201-400KW Diesel Generator
Cummins 201-400Kw Diesel Generator,Cummins Genset,Cummins Diesel Genset,Cummins Engine Diesel Generator
Shanghai Kosta Electric Co., Ltd. , https://www.ksdgenerator.com