Vehicle license plate recognition is based on image segmentation and image recognition theory. The image containing the license plate is analyzed and processed to determine the position of the license plate in the image, and the text characters are further extracted and recognized. The character images segmented from different license plate images are various in size, and the size variation range is large, which increases the difficulty of recognition. Although the image transformation method can be used to normalize all the segmented character images to the same size, the normalization process inevitably loses useful character information, causing image distortion, which does not help to improve recognition accuracy and waste time. , reducing the recognition speed.
This article refers to the address: http://
Based on the analysis of the characteristics of the license plate, this paper proposes a method to identify the letters and numbers in the license plate by using the stroke feature and structure knowledge of the characters. Experiments show that the method has fast recognition speed and high accuracy, and is not affected by the size of the character image, and has strong adaptability.
1 license plate character structure and recognition
The characters used in the Chinese mainland license plate include 59 Chinese characters, 25 English letters (the letter I is not used) and 10 Arabic numerals. There are 94 types, all of which are printed, with fixed structure and stroke specifications. Figure 1 is an image of all letters and numbers used in the license plate number. The structure of these characters has three types in the horizontal direction: left and right symmetry, left and right, small, left, and right. There are also three structures in the vertical direction, that is, upper and lower symmetry, upper and lower, and upper and lower. If the number "8" used in the license plate number is symmetrical, it is symmetrical.
As can be seen from Figure 1, there are two main types of strokes for all letters and numbers: straight strokes and arc strokes. Straight strokes can be divided into horizontal strokes, vertical strokes, left oblique strokes (equivalent to "æ’‡" in Chinese strokes) and right oblique strokes (equivalent to "æº" in Chinese strokes). The arc stroke is a curve segment, which is divided into two categories: open arc strokes and closed arc strokes. The so-called arc-opening stroke means that the arc stroke does not form a closed loop, such as the letter "C". Closed arc strokes form a closed loop, such as the number "0".

According to this feature of character images, this paper uses the following methods to classify letters and numbers step by step to form an identification decision tree, each character is a leaf:
(1) First, the number and position of the closed loops are searched for in the character image to be recognized.
(2) According to the result of searching for the closed loop, it is judged that the character is in the closed loop character class, the double closed loop character class, and the closed loop character class. (3) Processing is performed separately for each category.
(4) Double closed loop characters only have "8" and "B", so you can distinguish the two characters by extracting the vertical strokes. The left half of "B" has a long vertical and "8" does not.
(5) The characters of the single closed loop are "A", "D", "O", "P", "Q", "R", "0", "4", "6", and "9". These characters are divided into three categories according to the position of the closed loop: the closed loop is at the top; the closed loop is in the middle of the lower and closed loops, and then identified based on structural features and extracted stroke features.
. The characters in the upper part of the closed loop have "P", "R" and "9". If there is a closed loop in the upper part of the character image to be recognized, the vertical stroke is extracted from the left half; if there is no vertical stroke on the left part, the character is "9"; if the vertical stroke is drawn in the left half, continue to draw Right oblique stroke; drawn to the right oblique stroke, the character is "R"; otherwise it is "P".
. The characters in the lower part of the closed ring are "A", "4" and "6". If there is a closed loop in the lower half of the character image to be recognized, the vertical stroke is drawn from the right half; if there is a vertical stroke on the right side, the character is "4"; if no vertical stroke is drawn in the right half, continue Extract the horizontal stroke; extract the horizontal stroke, the character is "A"; otherwise it is "6".
. The characters in the middle of the closed loop have "D", "O", "Q", and "0". In practical applications, the images of "O" and "0" are identical and can be treated as the same character. If there is a closed loop in the middle of the character image to be recognized, firstly determine whether it is "Q" by using the upper and lower symmetry characteristics; if it is symmetrical up and down, it is "0" ("O") or "D"; then distinguish the characters according to the left and right symmetrical features "0" and "D".
(6) The characters without closed loops are "C", "E", "F", "C", "H", "J", "K", "L", "M", "N", " S", "T", "U", "V", "W", "X",
"Y", "Z", "l", "2", "3", "5", and "7" are used to identify these characters by extracting strokes. The specific steps are as follows:
· Extract horizontal strokes and vertical strokes.
· If the character image to be recognized does not have horizontal strokes and vertical strokes, the character is "S", "V" or "X".
· If the character image to be recognized has only horizontal strokes and no vertical strokes, the character is "2", "3", "7" or "Z".
· If the character image to be recognized has only vertical strokes and no horizontal strokes, the characters are "1", "C", "J", "K", "M", "N", "U", "W" Or "Y".
· The character to be recognized has both horizontal and vertical stroke characters of "5", "E", "F", "C", "H", "l" or "T".
. Identification of "S", "V" and "X". The left oblique stroke and the right oblique stroke are extracted, and "S" does not have these two strokes, so that "S" can be recognized. The intersection of the two oblique strokes of "X" is located in the middle of the character image, and the two oblique strokes of "V" intersect at the lower part of the character image to identify "X" and "V".
· Recognize 2", "3", "7", and "Z". Only "Z" of these four characters has two horizontal strokes, so that "Z" can be recognized by this. The cross between "3" and "7" The strokes are located at the top, and the "2" horizontal strokes are at the bottom, which in turn recognizes "2". For "3" and "7", the left oblique stroke is used for recognition. "7" has a left oblique stroke, and "" 3" no.
• Identify "1", "C", "J", "K", "M", "N", "U", "W", and "Y". These characters are divided into three categories according to the number of vertical strokes. "1", "C", "J", "K", and "Y" are all vertical strokes, "M", "N", and "U" are Two vertical strokes, and "W" have three vertical strokes, thus completing the recognition of "W".
For a character with a vertical stroke, determine whether the position of the stroke is on the left ("C" and "K"), the middle ("1" and "Y"), or the right ("J"). According to whether there is a right oblique stroke to distinguish "C" and "K", the length of the middle vertical stroke is divided into "1" and "Y".
. Since the character "N" has a right diagonal stroke, it is recognized from "M" and "U". For "M" and "U", the structural features are not recognized. This paper uses the ratio of the number of foreground pixels to the number of background pixels in the character image to judge. According to the characteristics of these two characters, only the upper half of the character can be calculated. · Identify "5", "E", "F", "G", "H", "I", and "T". Among these characters, only "E" has three horizontal strokes, "F" has two horizontal strokes, and the rest is a horizontal stroke. Among the remaining characters, they are divided into two groups according to the number of vertical strokes: "5", "L" and "T" are one vertical stroke, and "G" and "H" are two vertical strokes. The two vertical strokes of "H" are the same length, and the two vertical strokes of "G" are one long and one short, which is a sign distinguishing "G" and "H". The vertical stroke of "T" is in the middle, and the vertical strokes of "5" and "L" are on the left. The vertical stroke of "L" is long, and the vertical stroke of "5" is short, thus completing the recognition of "5", "T" and "L".
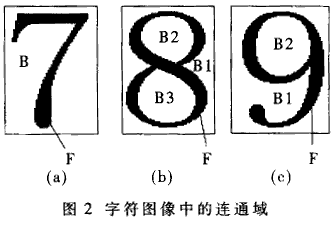
Searching for closed loops is actually searching for connected domains in character images. In the binary image of a character, assuming a character pixel value of "1" and a background pixel value of "0", then:
(1) There are only two connected domains in the character image without closed loop, namely the character connected domain and the background connected domain, and B and F in Fig. 2(a).
(2) There is only one connected domain in the character image of one closed loop, namely one character connected domain and two background connected domains, B1, B2 and F in Fig. 2(c).
(3) There are four connected fields in the character image with two closed loops, namely one character connected domain and three background connected domains, B1she, B2, B3 and F in Fig. 2(b).
The algorithm for searching for closed loops is as follows:
(1) Read a binary character image.
(2) Find a background pixel B with a pixel value of "0".
(3) Search for the connected domain of B, and mark all the pixels in the connected domain as background 1.
(4) Traverse the pixels in the image whose pixel value is "0".
(5) If all "0" pixels have been marked as background 1, the number of closed loops in the image is 0, and jump to (11).
(6) If there is a "0" pixel point B1 not marked as background 1, there is a closed loop.
(7) Search for the connected domain of B1, and mark all the pixels in the connected domain as background 2.
(8) Traverse the pixels in the image whose pixel value is "0".
(9) If all "0" pixels have been marked as background 1 or background 2, the number of closed loops in the image is 1, and jump to (11).
(10) If there are "0" pixels not marked as background 1 or background 2, the number of closed loops in the image is 2.
(11) End the search and return the number of closed loops.
Character stroke extraction can be found in the literature [1]
2 Identification test
Using this identification method, the author performed a recognition test on the characters separated from the license plate. The characters tested included a total of 7000 images of all 35 numbers and letters used in the license plate, with the largest frame being l00x100 pixels and the smallest being 20x20 pixels. There are 6,946 correctly identified, and the correct rate is over 99%. The images in which the errors are identified are mainly concentrated in the letters "0" and "D". By identifying these easily recognized characters for secondary recognition, the recognition accuracy can be greatly improved.
The core of the character recognition method proposed in this paper is to classify the character groups through the decision tree, and gradually narrow down the recognition range from the trunk until there is only one type of character at the end, that is, the recognition is successful.
The method has the following characteristics:
(1) It is not necessary to establish a recognition sample library, and the approximation recognition is performed according to the structural features of the characters themselves.
(2) It is not necessary to match and identify the character to be recognized with all the characters, thereby improving the recognition speed and accuracy.
Servo Emi Filters,Emi Servo Filters,Servo Motor Emi Filters,Servo Drive Line Filter
Zhejiang Synmot Electrical Technology Co., Ltd , https://www.synmot-electrical.com