With the advancement of DSP technology, DSPs with more computing power, lower power consumption and smaller size have emerged, making it possible to implant more accurate and complex automatic speech recognition (ASR) functions on 3G mobile phones. At present, basic ASR applications can be divided into three categories: 1. speech-to-text conversion (voice input); 2. speaker recognition; 3. voice command control (voice control).
These three types of features include the many ASR capabilities required for 3G. Typical examples of voice-to-text conversion are voice dialing and email dictation. The speaker recognition function can safely read out personal data in the memory through voice recognition, thereby satisfying the need for confidentiality applications such as ordering and banking services. Voice command control features include a voice interface that connects to the content of the Voice Extensible Markup Language (VXML) website, which supports services such as financial services and directory assistants. Currently VXML is used to standardize the voice tags of website content.
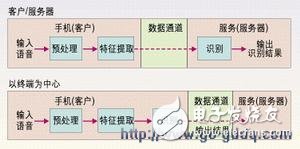
Two methods of speech recognitionThe ASR application design of 3G mobile phones can be divided into two categories, namely, terminal-centric and client/server-centric applications. As shown in Figure 1, the terminal-centric design method, the 3G mobile phone (terminal) performs the entire speech recognition process and sends the recognition result. In the client/server method shown in Figure 2, the terminal simply performs pre-processing feature extraction and then sends these parameters to the central server via an error-protected data channel, which ultimately completes speech recognition. If a client/server-centric design approach is adopted, the 3G handset should use a data channel instead of a mobile channel to send the voice to the server for identification, as the low-rate speech coding used by the mobile channel can seriously affect the performance of speech recognition.
The differences in various ASR systems are mainly reflected in the vocabulary. A simple network device may only require a 16-word lexicon to achieve the required speech recognition, while a 3G mobile phone requires a larger professional vocabulary. These words can be related to the speaker (training the speech recognition device to make them familiar with the user's voice characteristics) or speaker-independent (the speech recognition device can recognize anyone's voice), and the DSP's computational load is dictated by the vocabulary and training data. Increase and increase.
For example, according to the Hidden Markov Model (HMM), an example of a typical speaker-independent 100 command recognition application can be analyzed. Suppose the HMM model is placed in a sequence without jumping from left to right. There are 6 states and 5 mixed Gaussian distributions with diagonal covariance, including 39 features (13å”›-frequency log coefficient or MFCC, and its first order And second-order difference), with 16-bit precision, then the size of the HMM acoustic model is 100 & TImes; 5 & TImes; 5 & TImes; (39 + 2) & TImes; 2 = 240 kB.
In order to achieve real-time operation of input speech sample difference, window interception, MFCC extraction, probability calculation, and Viterbi search, it is typical to consume 10 million multiply-accumulate cycles (MMAC) of the DSP. For continuous speech recognition, thousands of triphone models and multiple grammar models require more storage space and require faster DSP processing speed.
Therefore, the success or failure of the ASR system in mobile phones depends largely on the function and design of the DSP. The third-generation system itself requires a DSP with better performance than the second-generation system, and the addition of the ASR function puts higher demands on the DSP. From a structural point of view, DSP performance requirements are fast processing speed, low power consumption, and high code density.
Using high-speed DSP is the keySince the system processes and samples speech in real time, the speech recognition system needs to have enormous computing power. The following figures and calculations assume a design approach around the terminal. If 20% of the DSP computing resources are allocated to a 10MMAC speech recognition system, then a DSP with 50MMAC is needed to meet this functional requirement and provide enough space to perform other DSP tasks required for 3G handsets, such as Handle soft cats. If a slower DSP, such as a 25MMAC DSP, is used, the number of commands in the vocabulary should be halved or the HMM parameters reduced, which can degrade overall system performance.
The speed of the DSP determines the complexity and performance of the speech recognition system. For example, if a basic talker-independent continuous speech recognition system requires 100 MMAC and 50% of the DSP computing resources are used to meet the needs of other DSP tasks for 3G handsets, then the DSP processing speed needs to reach 200 MMAC.
Cost, performance and efficiency tradeoffsThe faster the DSP is, the easier it is to utilize modern HMM techniques such as channel matching and sound domain matching. Therefore, in theory, the faster the DSP speed, the better the performance of the ASR system. However, parallel processing methods also play an important role in improving ASR system throughput. For example, a 200MHz DSP with 4 ALU (Arithmetic Logic Unit) has higher throughput than a DSP running at 400 MHz with only 1 ALU. Depending on the application, two to three single ALU DSPs provide performance similar to a DSP with 4 ALU. Compared to a DSP processor solution with 4 ALU, multiple single ALU DSPs will increase the cost of the handset, so there is a trade-off between cost and performance for marketable products.
In summary, when comparing a 600MHz single ALU DSP to a 300MHz but 4 ALU DSP, the ultimate goal that design engineers should always grasp is efficient computational throughput. DSPs with multiple ALUs may be the best solution.
Performance and power consumption
800 Puffs Vape,Electronic Smoke,Puff Bar Electronic Cigarette,Pure Smoke Electronic Cigarette
Guangzhou Yunge Tianhong Electronic Technology Co., Ltd , https://www.e-cigarettesfactory.com